
شرکت دیپسیک (DeepSeek) روز دوشنبه از یک مدل آزمایشی جدید با نام V3.2-exp رونمایی کرد که برای کاهش چشمگیر هزینههای پردازش در عملیات با متنهای طولانی طراحی شده است. این مدل هماکنون بهصورت open-weight در Hugging Face منتشر شده و مقاله پژوهشی مرتبط نیز روی GitHub در دسترس قرار گرفته است.
ویژگی کلیدی این مدل DeepSeek Sparse Attention نام دارد. این سیستم با استفاده از ماژولی به نام lightning indexer ابتدا بخشهای مهم از متن ورودی را انتخاب میکند و سپس یک سیستم انتخاب دقیق توکنها (fine-grained token selection) از میان آن بخشها، کلمات موردنیاز را برای پردازش در پنجره توجه بارگذاری میکند. نتیجه این روش آن است که مدل میتواند متنهای بسیار طولانی را با بار پردازشی کمتر مدیریت کند.
طبق آزمایشهای اولیه، استفاده از این تکنیک میتواند هزینه یک فراخوانی ساده API را در سناریوهای long-context تا ۵۰ درصد کاهش دهد. با توجه به اینکه مدل بهصورت آزاد منتشر شده است، انتظار میرود تستهای مستقل بهزودی صحت این ادعا را بررسی کنند.
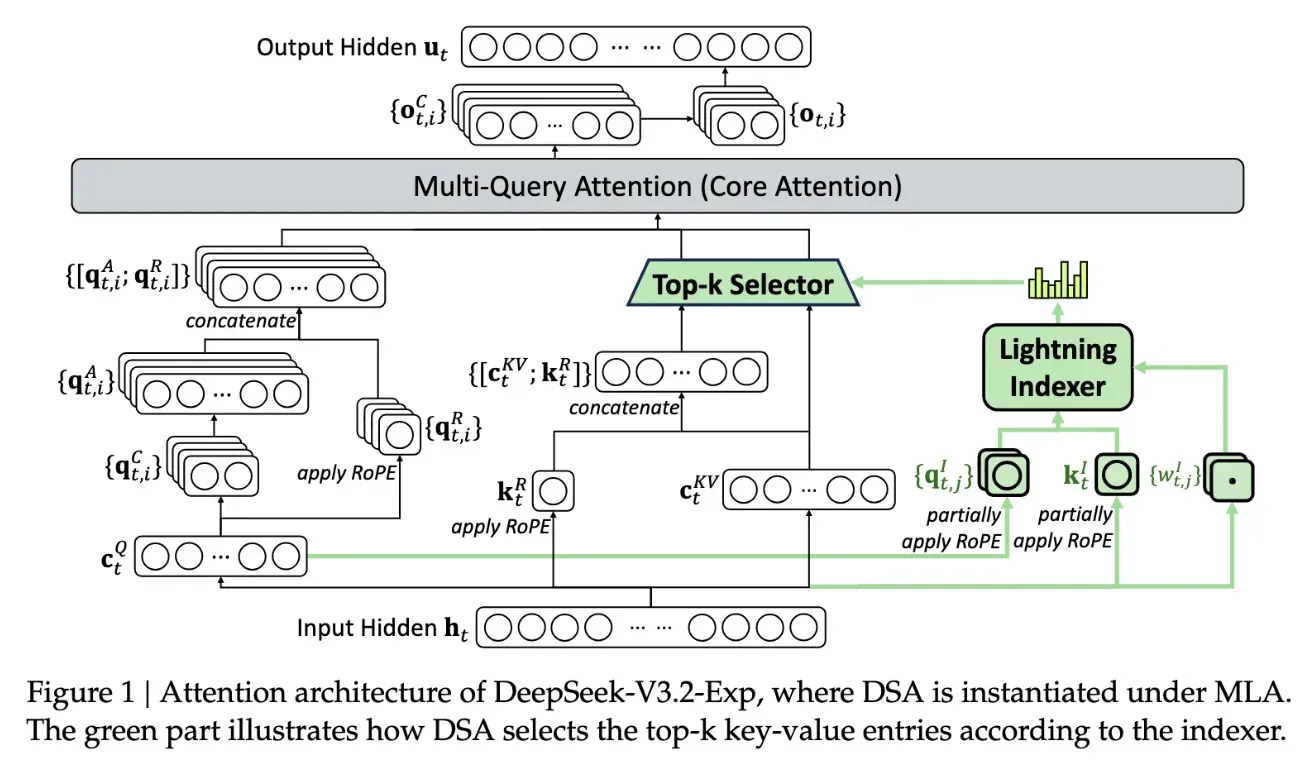
این دستاورد در حالی رخ میدهد که کاهش هزینههای inference (هزینه اجرای مدل آموزشدیده، نه آموزش آن) به یکی از بزرگترین چالشهای صنعت هوش مصنوعی تبدیل شده است. دیپسیک با این مدل نشان داده که حتی در معماری پایهای ترنسفورمرها نیز هنوز جای بهینهسازی زیادی وجود دارد.
دیپسیک که در چین مستقر است، پیشتر با معرفی مدل R1 در ابتدای سال خبرساز شد؛ مدلی که با تکیه بر یادگیری تقویتی و هزینهای کمتر از رقبای آمریکایی آموزش دیده بود. هرچند آن مدل برخلاف پیشبینیها انقلاب بزرگی در روشهای آموزش بهپا نکرد، اما Sparse Attention میتواند الهامبخش شرکتهای غربی برای کاهش هزینههای API باشد.
مدل V3.2-exp از دیپسیک با بهرهگیری از مکانیزم Sparse Attention نشان میدهد که آینده پردازش متنهای طولانی لزوماً وابسته به سختافزار پرهزینه و مصرف منابع بالا نیست. این نوآوری میتواند مسیر تازهای برای کاهش هزینههای API و بهینهسازی عملکرد مدلهای زبانی باز کند. اگرچه تأثیر نهایی آن نیازمند آزمایشهای گستردهتر توسط جامعه تحقیقاتی است، اما همین دستاورد میتواند الهامبخش شرکتهای دیگر در صنعت هوش مصنوعی باشد تا بهجای رقابت صرف بر سر اندازه مدل، بر کارایی و کاهش هزینههای inference تمرکز کنند.